Head-based sampling: Where the decision to collect and store trace data is made randomly while the root (first) span is being processed. However, software teams discovered that instrumenting systems for tracing then collecting and visualizing the data was labor-intensive and complex to implement. In aggregate, a collection of traces can show which backend service or database is having the biggest impact on performance as it affects your users experiences.
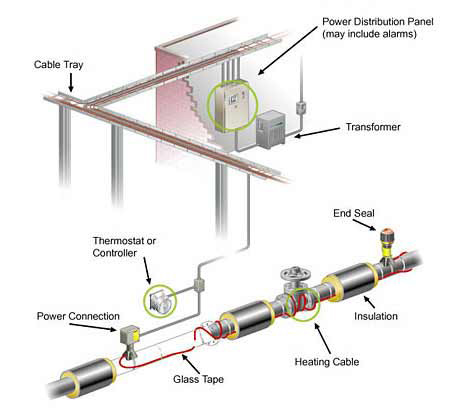
Remember, establish ground truth, then make it better! Its also a useful way of identifying the biggest or slowest traces over a given period of time. This diagram shows some important span relationships in a trace: As companies began moving to distributed applications, they quickly realized they needed a way to have not only visibility into individual microservices in isolation but also the entire request flow. Tail-based sampling, where the sampling decision is deferred until the moment individual transactions have completed, can be an improvement. Assess your application's microservice architecture and identify what needs to be improved. start time, end time) about the requests and operations performed when handling a external request in a centralized service, It provides useful insight into the behavior of the system including the sources of latency, It enables developers to see how an individual request is handled by searching across, Aggregating and storing traces can require significant infrastructure. Distributed tracing must be able to break down performance across different versions, especially when services are deployed incrementally. New Relic is fully committed to supporting open standards for distributed tracing, so that your organization can ingest trace data from any source, whether thats open instrumentation or proprietary agents. Since we deployed the tracing message bus to production, we were also able to easily scale up the number of Kinesis shards without incurring any downtime. Lightsteps innovative Satellite Architecture analyzes 100% of unsampled transaction data to produce complete end-to-end traces and robust metrics that explain performance behaviors and accelerate root-cause analysis. For our solution, we chose to match the data model used in Zipkin, which in turn borrows heavily from Dapper.

However, we still had to release all Knewton services before we could start integrating them with our distributed tracing solution. It also tells Spring Cloud Sleuth to deliver traces to Zipkin via RabbitMQ running on the host called rabbitmq. The drawback is that its statistically likely that the most important outliers will be discarded. A comprehensive observability platform allows your teams to see all of their telemetry and business data in one place. We had a lot of fun implementing and rolling out tracing at Knewton, and we have come to understand the value of this data. It covers the key distributed data management patterns including Saga, API Composition, and CQRS. Learn more about New Relics support forOpenTelemetry,OpenCensus, andIstio. The root span does not have a Parent Span ID. The consumers are backwards-compatible and can detect when a payload contains tracing data, deserializing the content in the manner of the Thrift protocols described above. We put a lot of thought into how we laid out our Guice module hierarchies so that TDist didnt collide with our clients, and we were very careful whenever we had to expose elements to the outside world. Some service meshes, such asIstio, also emit trace telemetry data. Trace ID: Every span in a trace will share this ID. The following are examples of proactive efforts with distributed tracing: planning optimizations and evaluating SaaS performance. Knewton built the tracing library, called TDist, from the ground up, starting as a company hack day experiment. Engineering organizations building microservices or serverless at scale have come to recognize distributed tracing as a baseline necessity for software development and operations. The answer is observability, which cuts through software complexity with end-to-end visibility that enables teams to solve problems faster, work smarter, and create better digital experiences for their customers. The Zipkin server is a simple, Spring Boot application: Microservices.io is brought to you by Chris Richardson. And isolation isnt perfect: threads still run on CPUs, containers still run on hosts, and databases provide shared access. Answering these questions will set your team up for meaningful performance improvements: With this operation in mind, lets consider Amdahls Law, which describes the limits of performance improvements available to a whole task by improving performance for part of the task. A separate set of query and web services, part of the Zipkin source code, in turn query the database for traces. TDist currently supports Thrift, HTTP, and Kafka, and it can also trace direct method invocations with the help of Guice annotations.

Out of the box, Zipkin provides a simple UI to view traces across all services. How can your team use distributed tracing to be proactive? Observability: In control theory, observability is a measure of how well internal states of a system can be inferred from knowledge of its external outputs. At other times its external changes be they changes driven by users, infrastructure, or other services that cause these issues. Because distributed tracing surfaces what happens across service boundaries: whats slow, whats broken, and which specific logs and metrics can help resolve the incident at hand. OpenTelemetry, part of theCloud Native Computing Foundation (CNCF), is becoming the one standard for open source instrumentation and telemetry collection. There are many ways to incorporate distributed tracing into an observability strategy. [As] we move data across our distributed system, New Relic enables us to see where bottlenecks are occurring as we call from service to service., Muhamad Samji,Architect, Fleet Complete. At the time, our Kafka cluster, which weve been using as our student event bus, was ingesting over 300 messages per second in production. What Amdahl's Law tells us here is that focusing on the performance of operation A is never going to improve overall performance more than 15%, even if performance were to be fully optimized.
As a service owner your responsibility will be to explain variations in performance especially negative ones. This dynamic sampling means we can analyze all of the data but only send the information you need to know.

Lightstep was designed to handle the requirements of distributed systems at scale: for example, Lightstep handles 100 billion microservices calls per day on Lyfts Envoy-based service architecture. We experimented with Cassandra and DynamoDB, mainly because of the institutional knowledge we have at Knewton, but ended up choosing Amazons Elasticache Redis. Throughout the development process and rolling out of the Zipkin infrastructure, we made several open-source contributions to Zipkin, thanks to its active and growing community.


And even with the best intentions around testing, they are probably not testing performance for your specific use case. Traditional log aggregation becomes costly, time-series metrics can reveal a swarm of symptoms but not the interactions that caused them (due to cardinality limitations), and naively tracing every transaction can introduce both application overhead as well as prohibitive cost in data centralization and storage.

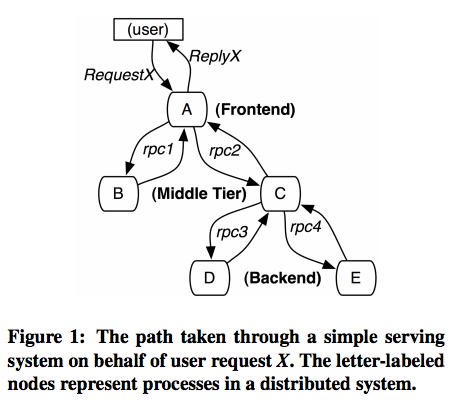
This means assigning a unique ID to each request, assigning a unique ID to each step in a trace, encoding this contextual information, and passing (or propagating) the encoded context from one service to the next as the request makes its way through an application environment. Its not as fast as Kafka, but the nature of our data made it acceptable to have an SLA of even a few minutes from publication to ingestion. Tail-based sampling: Where the decision to sample is made after the full trace information has been collected. These symptoms can be easily observed, and are usually closely related to SLOs, making their resolution a high priority. The following Spring Cloud Sleuth dependencies are configured in build.gradle: RabbitMQ is used to deliver traces to Zipkin. Contention for any of these shared resources can affect a requests performance in ways that have nothing to do with the request itself. The biggest disadvantage to customizing protocols and server processors was that we had to upgrade to Thrift 0.9.0 (from 0.7.0) to take advantage of some features that would make it easier to plug in our tracing components to the custom Thrift processors and protocols. You can learn more about the different types of telemetry data in MELT 101: An Introduction to the Four Essential Telemetry Data Types. New Relic gave us all the insights we neededboth globally and into the different pieces of our distributed application. In distributed tracing, a single trace contains a series of tagged time intervals called spans. These are changes to the services that your service depends on. That request is distributed across multiple microservices and serverless functions. With these tags in place, aggregate trace analysis can determine when and where slower performance correlates with the use of one or more of these resources. Lightstep analyzes 100% of unsampled event data in order to understand the broader story of performance across the entire stack. For example, when did the end-user response time slow for this customer? or did our latest nightly build cause this spike in failures? Answering these questions requires aggregate trace data analysis on a global scale beyond individual hosts, an understanding of historical performance, and the ability to segment spans without cardinality limitations. These interceptors readtracing data from headers and set them using the DataManager and vice versa. Thankfully, the newer version of Thrift was backwards-compatible with the older version, and we could work on TDist while Knewton services were being updated to the newer version. The same way a doctor first looks for inflammation, reports of pain, and high body temperature in any patient, it is critical to understand the symptoms of your softwares health. Still, that doesnt mean observability tools are off the hook. Sampling: Storing representative samples of tracing data for analysis instead of saving all the data. Planning optimizations: How do you know where to begin? Because of this, upgrades needed to start from the leaf services and move up the tree to avoid introducing wire incompatibilities since the outgoing services might not know if the destination service will be able to detect the tracing data coming through the wire. The next few examples focus on single-service traces and using them to diagnose these changes. Our Thrift solution consisted of custom, backwards-compatible protocols and custom server processors that extract tracing data and set them before routing them to the appropriate RPC call. In addition, traces should include spans that correspond to any significant internal computation and any external dependency. Although we didnt benchmark, we also think that this approach would have been marginally faster, since there are fewer classes delegating to tracing implementations. Modified thrift compilers are not uncommon; perhaps the most famous example is Scrooge. Simply by tagging egress operations (spans emitted from your service that describe the work done by others), you can get a clearer picture when upstream performance changes. The most important reasons behind our decision were. A single trace typically captures data about: Collecting trace data would be wasted if software teams didnt have an easy way to analyze and visualize the data across complex architectures.
Sitemap 15