I was confident that I threw this query statement into Clickhouse, but found that the simple query mentioned above takes 2-3s to execute, while executing the inner subquery alone only takes 0.3-0.4s; multiple conditions are tiled. When using GLOBAL JOIN, first the requestor server runs a subquery to calculate the right table. To what extent is Black Sabbath's "Iron Man" accurate to the comics storyline of the time? How to make distributed join of three or more tables as local join? More sub-query conditions will not significantly change the query time-consuming. Site design / logo 2022 Stack Exchange Inc; user contributions licensed under CC BY-SA. There are two ways to execute join involving distributed tables: Be careful when using GLOBAL. Question on solving partial derivative in probability theory.
Why is the in subquery executed multiple times in Clickhouse? ASOF JOIN uses equi_columnX for joining on equality and asof_column for joining on the closest match with the table_1.asof_column >= table_2.asof_column condition. In the author's application scenario, subquery A (user attribute table, behavior table filtering) is expensive to execute, so disabling prewhere optimization can bring performance improvements. If you do not need to match all the data that can be associated with the left table in the right table, it is recommended to use ANY, which greatly improves the execution speed. The execution plan should be that both subqueries A and B should be calculated once, and the outer query is calculated last.
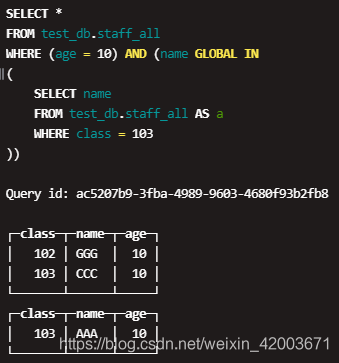
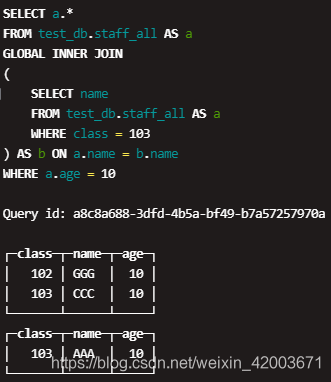
Therefore, in theory, when the number of machine cores is sufficient, for the following query statements (A and B both represent a certain sub-query statement), A and B sub-queries can be calculated in parallel. How can we send radar to Venus and reflect it back on earth? Subqueries are run on each of them in order to make the right table, and the join is performed with this table. by my testing, I found that if the two tables of distributed table engine join each other by global join and join with Join field is not primary key, it show same correct result. JFYI. FROM test.visits The [shopping] and [shop] tags are being burninated.

Host2: since source_local contains nothing on host2, result of the join will be empty. With an attitude of giving it a try, I replaced the above non-distributed table query with Global in and tried it. The final result therefore differs from the previous one: I think this request should solve your issue, JOIN WITH DISTRIBUTED TABLE , distributed_product_mode = 'local', We perfomed join with the Distributed table, but got the same result as for joining with local table. ) USING CounterID } else {
and then the initiator combines results from all shards. In our example, event_1_1 can be joined with event_2_1 and event_1_2 can be joined with event_2_3, but event_2_2 cant be joined. sel = document.selection.createRange();
function grin(tag) {
When transmitting data to remote servers, restrictions on network bandwidth are not configurable. Say we have a cluster cluster_name of two shards: host1 and host2.
Is it possible to turn rockets without fuel just like in KSP. CounterID, By clicking Post Your Answer, you agree to our terms of service, privacy policy and cookie policy. To learn more, see our tips on writing great answers. We've the same result as is in the first case with Distributed table. privacy statement. I am not sure if you can receive remind. FROM table1 ( Have a question about this project?

If the JOIN keys are Nullable fields, the rows where at least one of the keys has the value NULL are not joined. Join queries to improve query performance. And I can't post an answer myself. 4-5.

For example, table t1d, t2d, t3d are distributed table, and i have a query like this: then it can go with local join on each shard. }
If there is a one-to-one correspondence between the left table and the right table and there are no extra rows, the result of ANY and ALL is the same.
Clickhouse will work as you expected: it will execute your request on each shard locally and then combine results at initiator. myField.value += tag;
The setting join_use_nulls define how ClickHouse fills these cells. ORDER BY hits DESC
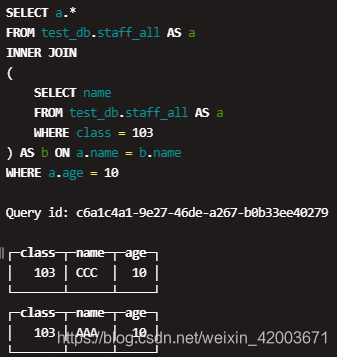
This is not to say that there is a bug in Clickhouse's prewhere optimization, because it is difficult for Clickhouse to judge whether it is better to use prewhere in this case, or it is better to use where directly. However, the query log of the query in Figure 1 shows that both A and B sub-queries have been executed twice . Can I dedicate my dissertation to my previous advisor? [ON (join_condition)].

https://clickhouse.com/docs/en/sql-reference/statements/select/join/#distributed-join https://clickhouse.com/docs/en/sql-reference/operators/in/#select-distributed-subqueries. But looking at the query log found that A was executed 2 times, B was executed 4 times, and C was executed 8 times. To reduce the volume of data transmitted over the network, specify DISTINCT in the subquery. myField.focus();
There is no restrictions which columns can be used. A typical business query can be expressed in the following SQL: Among them, those who are older than 10 years old and have participated in the "World Cup" are the portraits of the target population.

ASOF join is not supported in the Join table engine. Unless otherwise stated, join produces a Cartesian product from rows with matching join keys, which might produce results with much more rows than the source tables. But in the process, the author found that there was almost no explanation of the problem on the Internet, so I recorded it here, hoping to be helpful to others. Trending sort is based off of the default sorting method by highest score but it boosts votes that have happened recently, helping to surface more up-to-date answers.

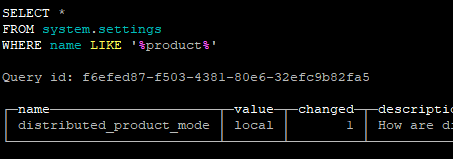
Generally, only the where query is written in the query statement, but during execution, Clickhouse will optimize the where query into a prewhere query based on whether there is partition key, primary key and other information in the condition, so as to improve the execution efficiency of the entire query. My switch going to the bathroom light is registering 120 V when the switch is off. Here, the user_id column can be used for joining on equality and the ev_time column can be used for joining on the closest match. Are Banksy's 2018 Paris murals still visible in Paris and if so, where? I checked a lot of information on the Internet, and finally an issue of Clickhouse on github gave me ideas [2]. For more information, see the External dictionaries section. SELECT *

if (document.selection) {
The test data and query results are the same.

This column: You can use any number of equality conditions and exactly one closest match condition. ), attribute table user_attr (user attributes, Such as gender, age, etc. 2-3. var myField;
Therefore, when the actual business scenario requires multi-table calculation, it is often replaced by in+subquery. /* ]]> */, aspC#+vc.net+Access+, ClickHouseReadIndirectBufferFromRemoteFS. Equal timestamp values are the closest if available. For example, consider the following tables: ASOF JOIN can take the timestamp of a user event from table_1 and find an event in table_2 where the timestamp is closest to the timestamp of the event from table_1 corresponding to the closest match condition. join_type table2 SQL2 executes double-distributed join. I'll try to explain with an example of joining 2 tables. subquery): Let's take a look at an example and play around with the distributed_product_mode setting and local/distributed tables. + tag
Closest equivalent to the Chinese jocular use of (occupational disease): job creates habits that manifest inappropriately outside work. However, keep the following points in mind: It also makes sense to specify a local table in the GLOBAL IN clause, in case this local table is only available on the requestor server and you want to use data from it on remote servers. FROM test.hits This is the same as the SQL standard JOIN behavior. Why does OpenGL use counterclockwise order to determine a triangle's front face by default? Conditions supported for the closest match: >, >=, <, <=.
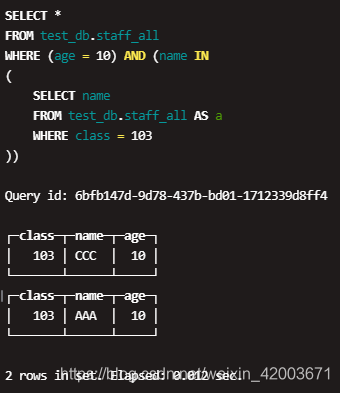
At present, the optimize_move_to_prewhere parameter of Clickhouse cluster can control whether to use prewhere optimization, but it is a global setting, turning off this switch will make all queries unable to use prewhere optimization. return false;
Therefore, in order to show the specified execution order, we recommend that you use the subquery to execute JOIN. The asof_column column always the last one in the USING clause. However, the official website document also states that for non-distributed tables , please use in to query instead of Global in. When using the ANY modifier to modify JOIN, if there are multiple data associated with the left table in the right table, the system only returns the first result that matches the left table. More complex join conditions are not supported. CounterID, myField.focus();

Clickhouse uses multi-core parallel computing to improve query performance. Usage suggestion: Delete all columns that are not required for JOIN from the subquery. For such cases, there is an external dictionaries feature that you should use instead of JOIN. As shown in Figure 2, when the query condition is user_id=123, the two data blocks on the left will be read, but not every row of them satisfies user_id=123. For the in subquery condition, replacing in with Global in can make the subquery execute first and save the result in a temporary table. The MergeTree table is composed of many Data Parts, which can be merged in the background to form a new Data Part; the data in each Data Part is sorted and stored according to the primary key, and the primary key has an index similar to the jump table, based on the key of the jump table , Divide the Data Part into multiple data blocks (Granule), the data block is the smallest unit of data reading in the MergeTree table.

To subscribe to this RSS feed, copy and paste this URL into your RSS reader. Seems like this query should work as you expected, but I prefer to accomplish this without the distributed_product_mode setting. SELECT }
table_1 table_2, UInt8, UInt16, UInt32, UInt64, UInt256, Int8, Int16, Int32, Int64, Int128, Int256.

In the recent business development, the author tried to use this method, but the performance was not as good as expected. It should be noted that the data block read after prewhere filtering contains rows that meet the conditions, but not all rows in the data block meet the query conditions . For distributed table engine, if tables join with column of no primary key , should it use global join or join? If you need to use GLOBAL IN often, plan the location of the ClickHouse cluster so that a single group of replicas resides in no more than one data center with a fast network between them, so that a query can be processed entirely within a single data center. ) ANY LEFT JOIN ASOF JOIN is useful when you need to join records that have no exact match. If the condition of the subquery hits the primary key of the outer query table, then the outer query will be executed once and the subquery will be executed twice.

This also explains why the time-consuming of multi-level nested queries increases exponentially with the number of levels. I think this is faster than above. Clickhouse executes where query is to do a full table scan of the data to filter out rows that do not meet the conditions; while prewhere query can use partition information and primary key information for efficient partition pruning, and filter out based on partition and primary key index before reading data Irrelevant data blocks reduce the amount of data read from the disk and improve query efficiency. The following table is the test results of the author using test data to write multiple nested query statements on the same table (the query statements in each layer are the same).

The final result: Short explanation: Each shard performs join of two local tables and then results are combined on the initiator. The join (a search in the right table) is run before filtering in WHERE and before aggregation. SELECT cursorPos += tag.length;
When multiple nested in+ subqueries are used, the query time will increase exponentially with the number of nesting levels. After the prewhere stage, all data blocks that meet the conditions are read from the disk, but not every row in it meets the condition of "user_id in A", so the row scan in the where stage must be performed to accurately filter out which rows The condition of "user_id in A" is met, and the calculation result of subquery A is needed at this time, so subquery A is executed for the second time . After some threshold of memory consumption, ClickHouse falls back to merge join algorithm. For example, SELECT count() FROM table_1 ASOF LEFT JOIN table_2 ON table_1.a == table_2.b AND table_2.t <= table_1.t. Find centralized, trusted content and collaborate around the technologies you use most. More like San Francis-go (Ep. It will not modify the algorithm but also will not throw unnecessary exceptions: Short explanation: Every host perfoms join of left local table with right subquery and then results are combined at the initiator host. SELECT

For simplicity, business data can be abstracted into three tables (all non-distributed tables ), user table user (user and social account table, social account refers to mobile phone, WeChat account, etc. These result transferred to the initiator and combined there. ( Initiator host sends query to each shard with left table replaced by the corresponding local table: Results are sent to the initiator host from all the shards. Announcing the Stacks Editor Beta release! When executing a JOIN query, because there is no optimization of the execution order compared with other stages: JOIN takes precedence over WHERE and aggregation execution. + myField.value.substring(endPos, myField.value.length);
Keyword OUTER can be safely omitted. But actually the execution plan can't show it.

Each shard of the table test_all AS a selects data from credit_ga.test_all_2 AS b and do join. rev2022.7.29.42699. LIMIT 10, https://www.cnblogs.com/JohnABC/p/7150921.html, https://clickhouse.yandex/docs/zh/query_language/select/. When you join distributed_table with other table (e.g. In some cases, it is more efficient to use IN instead of JOIN. When using a normal JOIN, the query is sent to remote servers. For multiple JOIN clauses in a single SELECT query: When running a JOIN, there is no optimization of the order of execution in relation to other stages of the query. myField.focus();
Then shards do join with this temporary table. For more information, see the Distributed subqueries section. tag = ' ' + tag + ' ';
To explain this problem, we must start with the data storage structure of the Clickhouse MergeTree engine. to your account.

Transmission does not account for network topology. At this time, using prewhere optimization can improve the execution efficiency. and my question is that: I hope on each shard can do local join like. What organelles(parts of a cell) did early cells most likely have?

For multi-level nested queries as shown below, theoretically the query time should be the sum of the time taken to execute A, B, and C separately plus the time taken for the outermost query (because the subquery C needs to be calculated first As a result, take "user_id in C" as a part of the condition into subquery B, then calculate the result of subquery B, take "user_id in B" as part of the condition into subquery A, and finally calculate subquery A, which is 3 Steps cannot be parallel). The columns specified in USING must have the same names in both subqueries, and the other columns must be named differently. Well occasionally send you account related emails.

for example: The text was updated successfully, but these errors were encountered: JOINs and primary keys are not related. var cursorPos = endPos;
It falls back to sorting by highest score if no posts are trending.

[CDATA[ */
Distributed JOIN There are two ways to execute join involving distributed tables: This is more optimal than using the normal IN. The search subquery is executed multiple times, and the articles found all say that in the Clickhouse distributed table query, the in subquery will be executed multiple times. var endPos = myField.selectionEnd;
}
Yeah, there is a difference in a way Clickhouse performs the query: At the point 2 right subquery will be executed only at one shard and then it will be spreaded across other shards. Reference : https://blog.csdn.net/lms1719/article/details/88634349, # MySQL Join Syntax if (document.getElementById('comment') && document.getElementById('comment').type == 'textarea') {
To avoid this, use the special Join table engine, which is a prepared array for joining that is always in RAM. }
Clickhouse has significant performance advantages in the OLAP query scenario, but Clickhouse does not perform very well in the large table join query scenario. Try to avoid large data sets when using GLOBAL IN.
Where developers & technologists share private knowledge with coworkers, Reach developers & technologists worldwide, I edit my question because this can support markdown format and no character limitation. FROM How to avoid merging high cardinality sub-select aggregations on distributed tables, ClickHouse: Usage of hash and internal_replication in Distributed & Replicated tables, Deduplication in distributed clickhouse tables, ClickHouse Distributed tables and insert_quorum, Is it possible to move data between two distributed tables in ClickHouse. Table credit_ga.test_all_2 is read 1 time. That means that you can use join of the Distributed table with local tables to achieve expected result: Change t2d_local and t3d_local with the corresponding local tables. Sign in The same is true for multi-level nested in subqueries. Already on GitHub? In the author's business scenario, the more time-consuming part of the query is the sub-query part (filtering user attributes and behaviors), so multiple executions of the sub-query directly lead to a longer query time. Does China receive billions of dollars of foreign aid and special WTO status for being a "developing country"? How make JOIN table in ClickHouse DB faster? else {
ClickHouse takes the
and creates a hash table for it in RAM. [1] Clickhouse official documentation, https://clickhouse.tech/docs/zh/sql-reference/operators/in/, [2] https://github.com/ClickHouse/ClickHouse/issues/13961, Reference: https://cloud.tencent.com/developer/article/1801026 Global in use in Clickhouse non-distributed table query-Cloud + Community-Tencent Cloud, The use of Global in in Clickhouse non-distributed table query, https://github.com/ClickHouse/ClickHouse/issues/13961. Connect and share knowledge within a single location that is structured and easy to search. If you need to restrict join operation memory consumption use the following settings: When any of these limits is reached, ClickHouse acts as the join_overflow_mode setting instructs. Are there any difference? CH does not use indexes or keys for joins. myField = document.getElementById('comment');
Making statements based on opinion; back them up with references or personal experience.  Sign up for a free GitHub account to open an issue and contact its maintainers and the community. The list of columns is set without brackets. Initiator host combines the results from all shard of local join, each shard do query "select * from t3_local where xxx group by xxx" and combines on the initiator(maybe this is synchronized with step1). Table credit_ga.test_all_2 AS b is read by each shard. Through online data query and local experiments, the use of Global in instead of in in the query finally solved the problem of multiple executions of sub-queries. Since it is a Distributed table, the result will be the same on both of the shards: Host1: source_local contains both rows with keys 1 and 2, exactly as a result of the subquery. It is a common operation in databases with SQL support, which corresponds to relational algebra join.
Sign up for a free GitHub account to open an issue and contact its maintainers and the community. The list of columns is set without brackets. Initiator host combines the results from all shard of local join, each shard do query "select * from t3_local where xxx group by xxx" and combines on the initiator(maybe this is synchronized with step1). Table credit_ga.test_all_2 AS b is read by each shard. Through online data query and local experiments, the use of Global in instead of in in the query finally solved the problem of multiple executions of sub-queries. Since it is a Distributed table, the result will be the same on both of the shards: Host1: source_local contains both rows with keys 1 and 2, exactly as a result of the subquery. It is a common operation in databases with SQL support, which corresponds to relational algebra join.  myField.focus();
Why can Global in solve the problem of multiple executions of subquery? I am mainly confused about the execution plan of three tables, this is the execution plan of query as below(note: t1d,t2d,t3d are distributed table): From my understanding, I think the step as below: t1_local and t2_local do local join on each shard as your reply, and I use explain syntax to find that t2d is written to t2_local, it is true, I am clear about this.
myField.focus();
Why can Global in solve the problem of multiple executions of subquery? I am mainly confused about the execution plan of three tables, this is the execution plan of query as below(note: t1d,t2d,t3d are distributed table): From my understanding, I think the step as below: t1_local and t2_local do local join on each shard as your reply, and I use explain syntax to find that t2d is written to t2_local, it is true, I am clear about this.
Sitemap 32